Data collector Base
- name:
- Data collector Base
- description:
- Inventory Data Collector toolkit for creating your own data collectors for iTop
- version:
- 1.4.0
- release:
- 2024-05-21
- state:
- stable
- github:
- https://github.com/Combodo/itop-data-collector-base
- diffusion:
- Client Store, Combodo Site, iTop Hub
- php-version-max:
- PHP 8.3
This module provides the base for creating an industrial data collection and synchronization application for iTop. Developers can rely on this module to perform all the heavy lifting related to the iTop data import and synchronization process in order to focus on the data collection.
Features
-
Simple API to make the creation of a new collector fast and easy.
-
Automatic creation and update of Synchronization Data Sources in iTop, based on JSON definitions.
-
Support small variations to the target Data Model via explicitely “Optional” attributes
-
Basic validation of the CSV format compared to the expected fields in the synchro data source.
-
Data upload and synchronization by chunks of
max_chunk_size(configurable). -
Extensible mechanism for handling configuration parameters.
-
Extensible list of placeholders in the JSON definition.
-
Automatic management (via placeholders) of the contact to notify and the user to use for running the synchro.
-
Validation of the minimum version of PHP and the needed extensions (as specified by the collector).
-
Command line tool to produce the JSON definition from an existing Synchro Data Source in iTop.
-
Capability to run independently: the configuration of the data sources, the data collection and the data synchronization.
-
Configurable log level (for console output or syslog logging)
-
Simple framework for quickly creating SQL based collectors
Revision History
| Release Date | Version | Comments |
|---|---|---|
| 2024-05-21 | 1.4.0 | * N°7338 - Use “itop_login” as fallback value if
no “synchro_user” defined in parameters * N°7339 - Improve error handling when user has no permission to write in data directory * N°7481 - Fix PHP requirement not taken into account (thanks to @Hipska) * N°7483 - Fix lookup table ignore error not ignored (thanks to @dw-itomig) * N°7482 - Ensure to dump source definition only when on debug (thanks to @Hipska) * N°3709 - Add the possibility to use an other date format than the default one * N°6115 - Add missing notify_contact_id_archive_flag in list of read-only fields * N°7234 - Add the possibility of mapping the same CSV column twice or more * N°7506 - Add method to check if a specific module is installed in iTop (thanks to @Hipska) |
| 2024-01-08 | 1.3.1 | * N°6226 Synchro of attributes marked as
optional * N°6420 dump_tasks : more info * N°6727 Fix config dump with special characters (#9) * Add missing default config parameters * N°6773 Log the synchro error message in debug mode * Fix EventIssue creation comment (#40) * N°6771 - Enhance synchro error detection based on synchro_exec output * N°6956 - Improve \CollectionPlan PHPDoc to ease dev experience in IDE |
| 2023-03-15 | 1.3.0 | * N°5710 - Enable writing
an extensible collector * N°5868 & 5950 - Add compatibility PHP 8.0 and PHP 8.1 * N°6012 - Support iTop authentication by token * N°5707 - Contact to notify can also be a Team * N°5139 - Add option to let data that is null also be null at the other side * N°5902 - Empty or header-only CSV source file do not stop following collects anymore * N°5995 & 5979 - Handles empty lookup table transparently * N°5600, 5709 & 5884 - Improve support of optional fields (present or not in iTop datamodel) * N°5738 - JSON collector mapping now supports index and * in field path * N°4391 & 5749 - Improve logged info in LOG_DEBUG mode * N°5995 - Empty lookup table no more generate PHP warning |
| 2022-03-07 | 1.2.4 | * N°4364 - Configurable eventissue object creation
when collector errors * N°4395 - Defaults values for datacollector base mode JSON * Defaults values for datacollector base mode CSV used only when there is no value in the input file * N°4710 - Handle empty json file in Fetch method |
| 2020-12-21 | 1.2.3 | * Fix compatibility with SSO set as default connection mode |
| 2020-10-20 | 1.2.1 | * Fix: Data synchro error message not handled (when reconciled on primary_key) |
| 2020-10-01 | 1.2.0 | * New JSON collector. * CSV collector configuration: format change + new parameters defaults / field /
ignored_columns / has_header* Add testconnection.php script |
| 2020-06-24 | 1.1.4 | * The path to the configuration file can now be
specified via the option --config_file on the command
line.* The location where to store the collected data is now a parameter in the configuration file: data_path.* Better checking of Data Source definitions to catch missing reconciliation keys * Option on the Lookuptable class to treat lookup errors as normal |
| 2020-04-30 | 1.1.3 | * New CSV collector * Configurable timestamp added in the logs * New option for usage: –help |
| 2019-11-07 | 1.1.2 | Fix “undefined constant TABLENAME_PATTERN” |
| 2019-10-28 | 1.1.1 | Contains upgrades from both 1.0.13 and 1.1.0 * Reject invalid characters for database_table_name |
| 2019-10-28 | 1.1.0 | Based on 1.0.9 * Added the specific class MySQLCollector which forces the DB connection to use UTF-8 characters |
| 2019-10-28 | 1.0.13 | * LookupTables can now be non case sensitive
(since MySQL is not) * Prevent a warning in SQLCollector for each “ignored” attribute * Improved support of iTop 2.4+ (obsolescence flag) |
| 2019-10-28 | 1.0.12 | * removed a warning in PHP 7.2 |
| 2018-06-26 | 1.0.11 | Added a debug trace (visible if
console_log_level=9) to show which mapping regular expression is
applied (when one is applied). Bug fix: properly handle utf-8 characters in the mapping table's regular expressions (/u modifier) Make the cUrl/SSL options configurable to suit all possible combinations and security considerations. |
| 2015-06-30 | 1.0.10 | New class of collector:
MySQLCollector which forces the retrieved data to be
encoded in UTF-8. |
| 2015-06-09 | 1.0.9 | Performance enhancement: retrieve only the needed fields when building a lookup table. |
| 2015-06-02 | 1.0.8 | Better checking of files access rights for writing. SQL connection string (for SQL collectors) is now fully configurable. |
| 2015-05-20 | 1.0.7 | Bug fixes: Support of backslashes in file names. Removed a warning by marking Utils::Substitute() static. |
| 2015-05-13 | 1.0.6 | Added the support of “ignoring” some rows in the data while re-processing them. SQL collector can be configured to safely ignore some fields. |
| 2015-02-16 | 1.0.4 | Added the configuration parameter
stop_on_synchro_error. |
| 2015-01-06 | 1.0.3 | Handling of non UTF-8 data (via the overloading of GetCharset()), error checking for the data import phase, optimization for iTop 2.1.0: ignoring any change in the database_table_name field. |
| 2014-11-03 | 1.0.2 | Added the base class SQLCollector for easily creating SQL based collectors. |
| 2014-10-11 | 1.0.1 | Added the method AttributeIsOptional
to handle variations in the target Data Model. |
| 2014-05-13 | 1.0.0 | First version |
Limitations
-
Data upload to iTop is done only via the syncho_import web service (could use the command line version or direct SQLcommands. TBD later, maybe)
-
Prior to the revision 3805 of iTop from SVN (from 2015-10-12!) the collector will NOT work properly if the account used to connect to iTop is not configured to use English as the language !!
-
Collector can only use the login_mode = “form”, it is not possible to use SSO authentication
-
Collectors are using synchro_import, but does not propagate yet date_format
Requirements
-
An access to the iTop web services (REST + synchro_import.php and synchro_exec.php)
-
We recommand to install php_curl to use the collector base parameter
itop_synchro_timeoutotherwise the timeout is hardcoded to 200 secondes and can't be overwritten by the collector.
php_curl, above it won't!Data Collector overview
How data collector works
Collectors are small ETL. Some parts can be customized by configuration, others by code.
-
⬇ Extract:
-
if using one of the bundled implementations (REST/JSON, SQL, CSV, …), you might only need to write some configuration
-
if you need a custom source, or to add some specific behavior, it can be coded in the collector class
-
-
🔁 Transform: mapping can either be done by configuration (if using an existing implementation) or by code (data mapping and lookup functionnalities)
-
⬆ Load: as the collector uses the iTop DataSynchro, this phase will be customized only by configuration
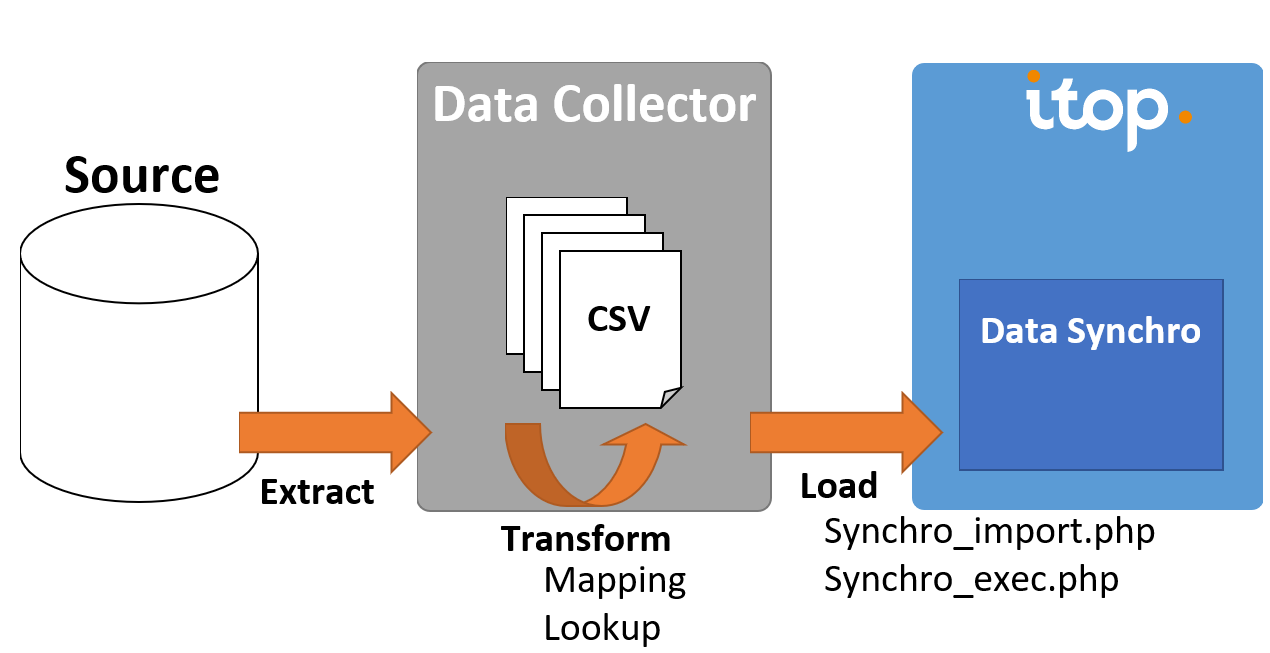
Data collector structure
Directories of a collector:
-
core: SDK files
-
toolkit: some tools for collector developers
-
conf: configuration
-
data: csv files containing collected data
-
collectors: collectors files
collectors directory
The specifics about a collector resides inside the “collectors” folder. This directory should contain at least :
-
collectors classes: for example
MyOwnCollector.class.inc.php -
datasynchro configuration: for example
MyOwnCollector.json -
main.php: file purpose is to register all the Collector classes for your module and load the corresponding classes (either via require_once(…) or by registering an auto-loader)
Should your collector rely on multiple collector classes, you
may group the php file under collectors/src/ and
the json files under collectors/json/.
Furthermore, files that extends an existing collector provided by
Combodo may be stored under
collectors/extensions/. See the writing
an extensible collector chapter.
Collectors examples
Combodo provides some already packaged collectors :
If no packaged collector is available for your data source, check those examples to implement quickly a base collector :
Creating a collector
Before starting
First question: How to get data from your source application. How can it be queried?
-
Directly querying the database in SQL?
-
Using REST and webservice, with returned data in JSON format?
-
Directly using CSV files produced by the application?
-
Using other sorts of webservices, such as for example
ripcord?
For each of the first 3 methods, a predefined collector exist already within the SDK, so writing your own based on those is mainly a matter of writing configuration files. For the last case, there is more work to do in PHP.
Second question: On which server will you install your collector?
-
The collector is a standalone application, which need to be started by a cron on a regular basis.
-
The collector must have access to the data of your source application
-
The collector must have web access to your iTop webservices, but does not need to be on the same machine.
-
The collector must be host on a machine compatible with collector base requirements
For each Source of Data which is collected and mapped before synchronization with iTop, the configuration can specify:
-
How to collect: where to get/find the source data
-
How to map:
-
Which source field should be copied in which iTop field
-
How a field value should be transformed into an iTop understood value
-
What default data to put in a given iTop field if not present in the source
-
The mapped data are put in an intermediate CSV file.
-
-
How to synchronize
-
Should the iTop field value be reset or left untouched, if later found empty in the source?
-
The exact configuration possibilities of How to
collect and How to map depends on the
collectors (JSON, CSV, OQL, custom).
Installation
-
download collector base archive
-
extract the archive files to the chosen collector machine
-
copy
conf/params.distrib.xmltoconf/params.local.xml -
create your collector class in the
/collectorsdirectory -
create
collectors/main.php -
create the corresponding datasynchro on the targeted iTop instance
-
extract the datasynchro config
-
update configuration (
conf/params.local.xml) -
launch the collector
Configuration
params.local.xml
params.distrib.xml contains the default values for the
parameters. Both files (params.distrib.xml and
params.local.xml) use exactly the same format, but
params.distrib.xml is considered as the reference and
should remain unmodified.Should you need to change the value of a parameter, copy and modify its definition in
params.local.xml. The values in
params.local.xml have precedence over the ones in
params.distrib.xmlMinimal configuration
params.local.xml is at minimum, the file to edit to
configure a collector.
And the following parameters must be set in this file:
- params.local.xml
-
<itop_url>https://localhost/</itop_url> <itop_login>admin</itop_login> <itop_password>admin</itop_password>
| Parameter | Meaning | Sample value |
|---|---|---|
| itop_login | Login (user account) for connecting to iTop. Must have admin rights for executing the data synchro. | admin |
| itop_password | Password for the iTop account. | |
| itop_url | URL to the iTop Application | https://localhost/itop |
Optional parameters
The following parameters can be redefined to alter the default behavior of the collector:
| Parameter | Meaning | Default value |
|---|---|---|
| max_chunk_size | Maximum number of elements to process in one iteration (for upload and synchro in iTop). If there are more elements than this number, the process will automatically iterate. | 1000 |
| itop_synchro_timeout | Timeout for waiting for the execution of one data
synchro task (in seconds)- requires php_curl |
600 |
| stop_on_synchro_error | Whether or not to stop when an error occurs during
a synchronization (yes or no). |
no |
| console_log_level | Level of ouput to the console. From -1 (none) to 9 (debug). | 6 (info) |
| console_log_dateformat | Logger timestamp format | [Y-m-d H:i:s] |
| eventissue_log_level | Level threshold to create event issues on remote iTop. From -1 (none) to 9 (debug). | -1 (none juste like before) |
| curl_options | When using cUrl to connect to the iTop Webservices
the cUrl options can be specified in this section. The syntax is
<CURLOPT_NAME_OF_THE_OPTION1>VALUE
1</CURLOPT_NAME_OF_THE_OPTION1> where VALUE_x are either: The numeric value of the option, or the string representation of the corresponding PHP “define” (case sensitive). It is possible to define several php_curl options like in the example below |
|
| data_path | New in 1.1.4 The path where to
store the temporary files generated by the collector. You can use
the special placeholder %APPROOT% to specify a path
relative to the root folder of the collector. |
%APPROOT%/data |
<curl_options> <CURLOPT_SSL_VERIFYHOST>0</CURLOPT_SSL_VERIFYHOST> <CURLOPT_SSL_VERIFYPEER>1</CURLOPT_SSL_VERIFYPEER> </curl_options>
date_formatConfiguration for a SQL collector
The configuration parameters for the SQL Collectors are:
| Parameter | Meaning | Default Value |
|---|---|---|
| sql_engine | The PDO driver/engine to use for the database connection. | mysql |
| sql_host | The name or IP address of the database server to connect to. | localhost |
| sql_database | The name of the database to connect to. | empty |
| sql_login | The login to use when connecting to the database | root |
| sql_password | The password to use when connecting to the database | n/a |
| sql_connection_string | New in 1.0.8 The format of the
PDO connection string. 3 placeholders are available inside the
format string: %1$s = sql_engine,
%2$s= sql_database and %3$s =
sql_host |
%1$s:dbname=%2$s;host=%3$s |
| collector_class_query | The query to run for the collector which PHP class
is collector_class. For example :
MyCollectorClass_query |
|
| collector_class_ignored_attributes | New in 1.0.6 To take into account the possible variations of the data model, without re-writing a collector each time, it is possible to mark some of the collected attributes as “optional” so that the collector can run even if the corresponding attribute does not exist in the data model. Supply an array of attribute codes to ignore, here. |
sql_connection_string. For example:
%1$s:dbname=%2$s;host=%3$s;port=3307
For versions prior to 1.0.8, to specify a port number (other
than the default port), use the syntax host;port=xxxx
for the sql_host parameter. Example:
localhost;port=3307
MySQLCollector. This class is identical to
SQLCollector except that it forces the retrieved data
to be encoded in UTF-8 by issuing the SQL command SET NAMES
'utf8' at the beginning of the each connection to the
database. To avoid any problem with the character set of the data,
it is recommended to use this new class for all connections to a
MySQL/MariaDB database.Configuration for a JSON collector
| Parameter | Meaning |
|---|---|
| jsonfile | Define relative or absolute path to the json file to parse for the collector which PHP class is collector collector_class. This parameter or jsonurl is mandatory |
| jsonurl | The URL of json file to parse for the collector which PHP class is. This parameter or jsonpath is mandatory |
| jsonpost | Xml of params to post with the url in order to get Json file <name_of_param>value</name_of_param> |
| command | The CLI command to execute BEFORE parsing json file for the collector which PHP class is collector_class. This parameter is optional |
| path | path in order to find data to synchronize in json separator is / and * replace any word by example aa/bb for {“aa”:{“bb”:{mydata},“cc”:“xxx”} and aa/ * /bb for {“aa”:{cc“:{“bb”:{mydata1}},”dd“:{“bb”:{mydata2}}} |
| fields | xml which describes connection between name in
json and name in itop
<name_in_itop>name_in_json</name_in_json> It can be a path as the path parameter, so include
level /, * and index (number), when the structure has no key |
| defaults | allow to specify itop fields for which we want to
set fixed values. It can be used in combination with a mapping, for
the case where a particular Blabla Site has no value
for this field. |
Configuration for a CSV collector
Inside your collector configuration section you can set below parameters:
| Parameter | Meaning | Default Value | |
|---|---|---|---|
| csv_file | The csv file to be parsed by the collector. You can specify an URL, the full path of this file (/tmp/myfile.csv) or a relative path to the collector collector_class. This parameter is mandatory | ||
| command | The CLI command to execute BEFORE reading/parsing csv file. This parameter is optional | ||
| encoding | The csv file encoding. This parameter is optional | UTF-8 | |
| separator | The separator to use for the csv file to parse.
This parameter is optional. Note: you can use the literal string
TAB to specify that the separator is the ASCII
character tab (0x09). |
; | |
| defaults | for each synchro field you can specify a default value to be used during synchro step | ||
| fields | This is a mapping section between data synchro fields and the one found in the CSV file. | ||
| ignored_columns | This section describes which CSV fields you decide to ignore. | ||
| has_header | Indicates whether there is CSV header that describes your column names or not. | true |
DataSynchro configuration
A collector is a PHP class that provides the data for a given
iTop Synchronization Data
Source. Collector classes are derived from the abstract
Collector class. Each collector is associated with a
Synchronization Data Source, defined in JSON format. The default
implementation simply looks for a JSON file with the same name as
the collector class and the extension “.json”, in the
collectors folder.
The simpler way to create this definition file for a Synchro Data Source, is to export the definition of an existing data source.
-
Create the synchronisation data source in iTop, adjust its parameters (attributes mapping, deletion policy, full load interval, etc.) to suit your needs
-
Use the command line tool
dump_tasks.php(available in thetoolkitfolder) to produce the JSON file:
console_log_level in params.local.xml low
enough < 7 on Linux and < 6
on WAMP (default is 6)Otherwise the .json generated will contain dummy lines (notice/debug) which will crashes the execution.
php toolkit/dump_tasks.php --task_name="name of the task to export" > collectors/myCollector.json
This definition file is in JSON format.
database_table_name, this name MUST BEGIN
WITH <table-prefix>synchro_data. Where
<table-prefix> is the prefix used for all tables
in iTop (configured using the db_subname parameter in
the iTop configuration file).no update and no lock.Inside your Synchro Data Source definition file you can use special placeholders to make the Data Source configurable by the user of the application, or to adjust its behavior via some special settings:
| Placeholder code | Meaning | Sample value |
|---|---|---|
$version$ |
The version of the module. Useful for versioning your application, for example in the “description” of the synchro data source. | 1.0.0 |
$synchro_user$ |
The user to run the synchro, specified by its login in the configuration file. The identifier of the User object is available via this placeholder. | cron-user |
$contact_to_notify$ |
The contact to notify, specified by its email address in the configuration file. The identifier of the contact is supplied via this placeholder. | itop-admin@demo.com |
$full_load_interval$ |
The delay (expressed in seconds) between two complete imports of the data. The objects which have not been detected by the collector during a timespan longer than this interval will be considered as obsolete and marked as such in iTop. Adjust this value depending on the scheduling recurrence. | 604800 |
$prefix$ |
The prefix for the name of all
Synchronization Data Sources in iTop. Required to run several
instances of the collector (to collect information from several
vSphere servers). Prefix all datasynchro names with
$prefix$ in each .json file |
vSphere1 |
Registering collectors
All of the collector classes must be registered. To register
your collector, add in collectors/main.php a call to
the static method Orchestrator::AddCollector(). The
two parameters are:
-
The order in which the collector should be run (when you need to run several collectors one after the other)
-
The name of the class (derived from
Collector) in which the collector is implemented.
When writing an extensible collector (see below), this step can be skipped as the registration is handled by the collection plan itself
Testing the collector
Testing iTop REST API connection
You may encounter network/authentication issues to reach the iTop server you need to synchronize. To test that connection please use below command:
* connection OK: JSON answer is displayed in the ouput
php toolkit/testconnection.php curl_init exists: 1 /home/combodo/workspace/collector/itop-data-collector-base/toolkit/testconnection.php:12: array(4) { 'version' => string(3) "1.0" 'operations' => array(7) { [0] => array(3) { 'verb' => string(11) "core/create" 'description' => string(16) "Create an object" 'extension' => string(12) "CoreServices" } ...
* network issue: HTTP error code displayed (among other logs)
php toolkit/testconnection.php UNIX system curl_init exists: 1 Problem opening URL: https://localhost/iTop/webservices/rest.php?version=1.0 error msg: Failed to connect to localhost port 443: Connection refused curl_init error code: 7 (cf https://www.php.net/manual/en/function.curl-errno.php)
* credential issue
php toolkit/testconnection.php UNIX system /home/combodo/workspace/collector/itop-data-collector-base/toolkit/testconnection.php:12: array(2) { 'code' => int(1) 'message' => string(20) "Error: Invalid login" } Calling iTop Rest API worked!
* permission issue
php toolkit/testconnection.php UNIX system curl_init exists: 1 /home/combodo/workspace/collector/itop-data-collector-base/toolkit/testconnection.php:12: array(2) { 'code' => int(1) 'message' => string(136) "Error: This user is not authorized to use the web services. (The profile REST Services User is required to access the REST web services)" } Calling iTop Rest API worked!
Fix : Add the “REST Services User” profile to the user set in
the conf/params.distrib.xml file.
Troubleshooting datasynchro issues
Set the console_log_level to 7 or more to get more
information about the synchro_import. From level 7 and above, the
collector executes synchro_import with
output=details instead of output=redcode,
and so will get more information about the synchronization errors
and warnings on iTop side. Those details are then log on the
collector side. With a console_log_level below 7, some
warnings may never be recorded at all, even on iTop side, and your
iTop objects can remain not-synchronized without explanation.
To learn more, see this dedicated page : Troubleshooting a Data Synchro
Usage
To launch the data collection and synchronization with iTop, run the following command (from the root directory where the application is installed):
php exec.php
The following (optional) command line options are available:
| Option | Meaning | default value |
|---|---|---|
| --config_file | Specify the full path to the configuration file.
The file conf/params.local.xml is used by default if
this parameter is omitted. |
empty |
| --console_log_level=<level> | Level of ouput to the console. From -1 (none) to 9 (debug). | 6 (info) |
| --eventissue_log_level=<level> | Level threshold to create event issues. From -1 (none) to 9 (debug). | 6 (info) |
| --collect_only | Run only the data collection, but do not synchronize the data with iTop | false |
| --synchro_only | Synchronizes the data previously collected (stored
in the data directory) with iTop. Do not run the
collection. |
false |
| --configure_only | Check (and update if necessary) the synchronization data sources in iTop and exit. Do NOT run the collection or the synchronization | |
| --max_chunk_size=<size> | Maximum number of items to process in one pass, for preserving the memory of the system. If there are more items to process, the application will iterate. | 1000 |
| --help | Usage mode to display exec.php help. |
Advanced configuration
Reset or untouch
For How to synchronize, this is how you can specify
fields that you don't want the DataSynchro to modify if they are
empty on the source
-
In general, when the pushed value is an empty string, the iTop field will be reset to the iTop field default value. Check your iTop version wiki for exceptions.
-
Starting from iTop 3.0, when the pushed value in the csv, is exactly the <NULL> string, then synchro_import.php will put
NULLin the replica table and the iTop field will remained untouched.
Since version 1.3.0 of collector base, it is possible to specify fields which if empty in the source, should be mapped to <NULL> so that the iTop field value is left unchanged.
- param.config.xml
-
<iTopPersonCollector> <nullified_attributes type="array"> <attribute>phone</attribute> <attribute>manager_id</attribute> </nullified_attributes> </iTopPersonCollector>
Collectors with multiple sources : placeholders
Sample configuration file:
- conf/params.local.xml
-
<?xml version="1.0" encoding="UTF-8"?> <!-- Local values for parameters. --> <!-- The values defined in this file have precedence over the ones defined in params.distrib.xml --> <parameters> <itop_url>https://localhost/trunk</itop_url> <itop_login>admin</itop_login> <itop_password>admin</itop_password> <console_log_level>9</console_log_level> <eventissue_log_level>3</eventissue_log_level> <contact_to_notify>test@test.com</contact_to_notify> <synchro_user>admin</synchro_user> <json_placeholders type="hash"> <test>Test 1</test> </json_placeholders> </parameters>
Sample
Synchro Data Source definition file, notice the use of the
$version$, $synchro_user$,
$contact_to_notify$ and $test$
placeholders
Event issue creation
eventissue_log_level has been added to be able to track collector issues from iTop console directly. this could be useful to administrate iTop application or even monitor it.
Let's say parameter 'eventissue_log_level' is set to ERROR (3) level. collector execution will trigger an event issue object creation for each ERROR log printed with some detailed information. this is a way to centralize any collector feedback during any step of collector execution (configuration, collect, data synchronization).
Example of EventIssue created
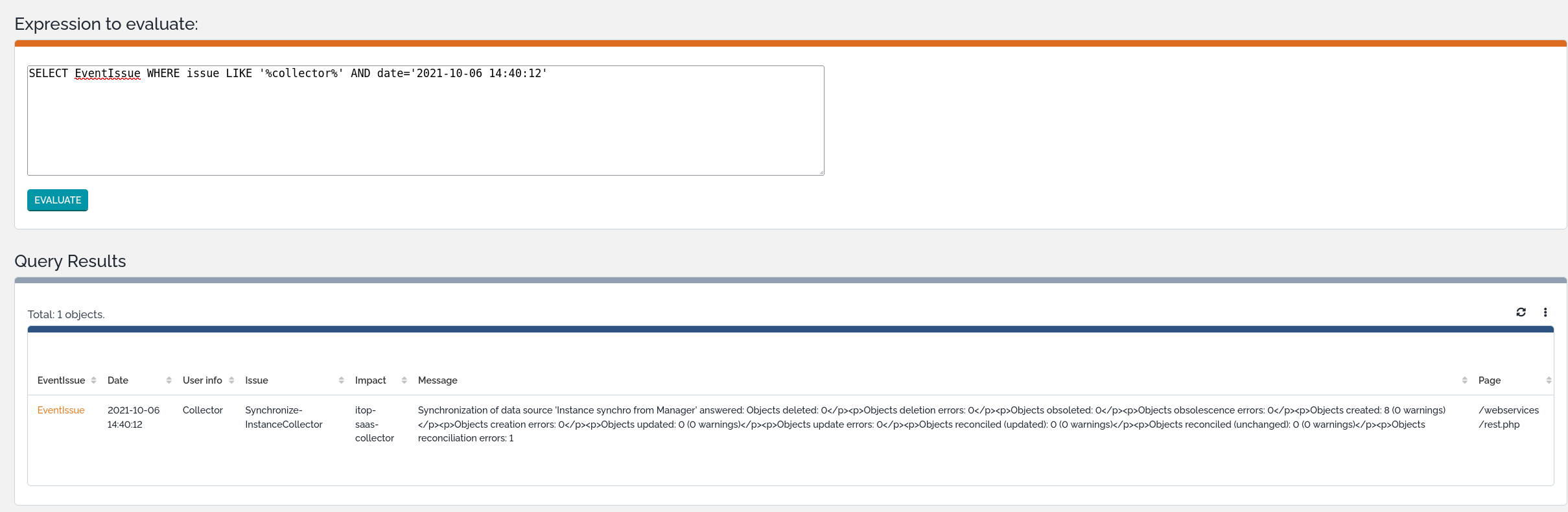
Running several instances of the collector
In many circumstances it may be useful to run several times the collector with a different set of parameters. For example to collect persons information from several LDAP servers (iTop Data Collector for LDAP) or Virtual Machines information from several vSphere servers (iTop Data Collector for vSphere).
Prior to version 1.1.4 of the framework, you had to completely
duplicate the collector application and adjust the file
conf/params.local.xml on each copy.
Since version 1.1.4 you can have just one single copy the of the
collector application and specify a different configuration file
(with the command line option --config_file) for each
collection to run (i.e. one configuration file per LDAP or vSphere
server).
However, to avoid any troubles during the collection of the data and the synchronization with iTop, the following parameters must be properly configured inside the configuration file:
-
Use a different
<prefix>inside each different configuration file. This ensures that a specific set of Synchronization Data Sources will be created for each configuration file. -
Use a different
<data_path>variable for each configuration file. This will cause the collector to store all its collected data (including some temporary files) in a dedicated directory. This prevents one instance of the collector to overwrite the data of another one. You can use the syntax<data_path>%APPROOT%/data/collector1</data>to have a subfoldercollector1created inside thedatafolder.
Custom collector class
Your collector must be a class derived from
Collector. It must implement (at least) the
Fetch() method. Fetch must return either, for each
object to load, an array using the format attribute_code
=> value or false when the end of the set of
objects has been reached.
The array returned by Fetch() must contain:
-
an entry
primary_keythat uniquely identifies the object being synchronized with iTop. The entry can contain whatever unique ID you can obtain from the inventory collection, or a unique identifier generated as a combination of the various fields of the object. It's up to the collector application to guarantee the unicity of this identifier (and its stability in time) -
an entry for each attribute of the object to be loaded in iTop.
The sample code below generates a set of 10 servers, named 'Server 1', 'Server 2' … 'Server 10', and initialized 3 fields of the servers: their name, their organization (always 'Demo') and their description.
- main.php
-
class MyCollector extends Collector { protected $idx; public function Prepare() { $bResult = parent::Prepare(); $this->idx = 0; return $bResult; } public function Fetch() { if ($this->idx < 10) { $this->idx++; return array( 'primary_key' => $this->idx, 'name' => 'Server '.$this->idx, 'org_id' => 'Demo', 'description' => 'Test Collector' ); } return false; } } // Register the collector, as the 1st to run Orchestrator::AddCollector(1, 'MyCollector');
GetCharset() of your collector to return the
name of the character set (must return a value accepted by iconv on
the iTop server)Data Mapping
Raw data collected by inventory scripts sometimes require a
normalization before being imported into iTop, in order to obtain
homogenous data. The framework provides the helper class
MappingTable for performing simple normalizations
tasks.
A mapping table is configured (in the
params.xxx.xml configuration file) as an ordered list
of patterns, with a value associated to each pattern. The “clean”
value returned by the mapping table is the value associated with
the first pattern that matches the input value. Patterns are
expressed as regular expressions. Values can use the placeholders
to refer to some part of the matched pattern (%1$s is
the whole pattern, %2$s the first group inside the
regular expression, etc.).
So, the format of each entry in the mapping table is:
<pattern>/regular_expression/replacement_string</pattern>
Where:
-
regular_expression is a PCRE regular expression to be matched against the input value,
-
replacement_string is the resulting value if the input value matches the regular expression.
-
Note: any character can be use as a delimiter around the regular expression, not only
/. But the delimiter character can be present neither in the expression itself nor in the replacement string or the result will be undetermined.
Example of configuration (Brand normalization):
- params.xxx.xml
-
<brand_mapping type="array"> <!-- Syntax /pattern/replacement where: any delimiter can be used (not only /) but the delimiter cannot be present in the "replacement" string pattern is a RegExpr pattern replacement is a sprintf string in which: %1$s will be replaced by the whole matched text, %2$s will be replaced by the first matched group, if any group is defined in the RegExpr %3$s will be replaced by the second matched group, etc... --> <pattern>/IBM/IBM</pattern> <pattern>/Hewlett.Packard/Hewlett-Packard</pattern> <pattern>/Dell/Dell</pattern> <pattern>/.*/%1$s</pattern> </brand_mapping>
This example file performs the following normalization:
-
Every string containing “IBM” is transformed into “IBM”,
-
Every string containing “Hewlett”, followed by any character, followed by “Packard” is transformed into “Hewlett-Packard”,
-
Every string containing “Dell” is transformed into “Dell”,
-
All other strings are kept as is.
Using a mapping table in your code
-
Create an instance of the
MappingTableclass, passing it the name of the XML tag in which to look for its configuration (inside the XML param file) -
Use the
MapValuemethod to process each value as needed (the second parameter is the default value, when no match is found in the mapping table).
Usage example:
- testcollector.class.inc.php
-
// Turns the raw brand string ('brand_id') into a normalized brand // Use 'Other' for brands not found in the normalization table class TestCollector extends SQLCollector { protected $oBrandMapping; public function Prepare() { $bRet = parent::Prepare(); // Create the MappingTable once at the initialization of your collector $this->oBrandMapping = new MappingTable('brand_mapping'); return $bRet; } public function Fetch() { $aData = parent::Fetch(); if ($aData !== false) { // Then process each collected brand $aData['brand_id'] = $this->oBrandMapping->MapValue($aData['brand_id'], 'Other'); } return $aData; } }
Advanced Lookups
The data synchronization mechanism embedded in iTop is not
capable of performing reconciliations based on multiple fields
(like searching for a Model based on both the Brand name and the
Model name). The LookupTable class provides this
reconciliation capability for any number of fields.
The class LookupTable builds a lookup table by
retrieving the specified fields of a set of iTop objects, and
storing the resulting identifier of the objects in iTop.
An instance of LookupTable is created by specifying
an OQL query (the set of iTop objects to retrieve) and the fields
of the objects that will be used for the mapping.
LookupTable instance is the list of fields to be
passed later on when performing a Lookup(…)Once the LookupTable has been initialized, a call
to the Lookup($aData, array(Field1, Field2, …),
destField) method will replace in $aData the
value of the column destField by identifier of the
iTop object whose specified fields match the values passed in
$aData as the columns Field1,
Field2….
Lookup method returns false if not
corresponding lookup was found. In such a case the code can either
supply a default value, of throw an exception
IgnoredRowException to tell the collector to reject
the whole line of collected data.LookupTable accepts
one extra (optional) parameter: $bIgnoreMappingErrors
(default to false). If this parameter is set to
true, the LookupTable will consider that
lookup errors are normal and will not report them as
warnings (but still list them in debug mode). This can be useful
when the Lookuptable is used for filtering the collected data
against a catalog defined in iTop. In such a case, lookup errors
are the expected behavior.Example
In iTop, the operating system version is represented as a
version depending on an OS family object. We can have the
following objects in iTop:
-
Windows, versions 7.0 and 8.1,
-
Debian version 12.0.0.
This will be stored in iTop as shown below:
| Object class | id | name |
|---|---|---|
| OSFamily | 1 | Windows |
| OSFamily | 2 | Linux Debian |
| Object class | id | osfamily_id | name |
|---|---|---|---|
| OSVersion | 1 | 1 | 7.0.0 |
| OSVersion | 2 | 1 | 8.1.0 |
| OSVersion | 3 | 2 | 12.0.0 |
Now let's imagine that our collector script gives us the two informations: 'Windows' and '8.1.0'. We can store the 'Windows' text string in the 'osfamily_id' field of the data synchro table and configure the synchro data source to perform the reconciliation based on the 'name' (this will properly replace 'Windows' by 1).
But to retrieve the identifier of the version 8.1.0 of Windows
(which is 2 in our example) we need both the OS Family ('Windows') and the version
number ('8.1.0'). The Synchronization Data Source is not capable of
doing this composite lookup, this where the
LookupTable comes into play.
$oOSVersionLookup = new LookupTable('SELECT OSVersion', array('osfamily_id_friendlyname', 'name'));
This will build - in memory - the following table:
| lookup_key | id |
|---|---|
| Windows_7.0.0 | 1 |
| Windows_8.1.0 | 2 |
| Debian_12.0.0 | 3 |
So if we have in $aData the following values:
| osfamily_id | osversion_id |
|---|---|
| Windows | 8.1.0 |
Calling:
$oOSVersionLookup->Lookup($aData, array('osfamily_id', 'osversion_id'), 'osversion_id', 0);
Will place in the column 'osversion_id' the result of the lookup
for the values $aData['osfamily_id'] and
$aData['osversion_id'].
$aData will then contain the following values:
| osfamily_id | osversion_id |
|---|---|
| Windows | 2 |
We then have to configure the Synchro Data Source so that it
accepts the oversion_id as-is without performing any
reconciliation on it.
Lookup(…) must contain the line number inside the CSV
file being processed. This is used internally to perform some
initializations only once when processing the first line of the
file.The advanced reconciliation works by retrieving (via the
REST/JSON API), the objects to be
matched against the composite key, after the data
collection but before pushing the data to iTop. Therefore,
in order to use this advanced lookup mechanism, you must
tell the framework that the collector has to reprocess the
collected data before the actual synchro. This is achieved by
overloading the method MustProcessBeforeSynchro of the
collector; and returning true.
The collector framework provides two additional methods which can be overloaded:
-
InitProcessBeforeSynchrois called after the data collection, but before starting to reprocess each line of the collected data. This is the plece where to create theLookupTableinstance -
ProcessLineBeforeSynchrois called for each line of the collected data (including the header line of the CSV file, which index is zero)
Usage Example
The following code fragment shows to use cases of lookup tables altogether: one for brand + model and one for OS family + OS version.
- testcollector.class.inc.php
-
protected function MustProcessBeforeSynchro() { // We must reprocess the CSV data obtained from the inventory script // to lookup the Brand/Model and OSFamily/OSVersion in iTop return true; } protected function InitProcessBeforeSynchro() { // Retrieve the identifiers of the OSVersion since we must do a lookup based on two fields: Family + Version // which is not supported by the iTop Data Synchro... so let's do the job of an ETL $this->oOSVersionLookup = new LookupTable('SELECT OSVersion', array('osfamily_id_friendlyname', 'name')); // Retrieve the identifiers of the Model since we must do a lookup based on two fields: Brand + Model // which is not supported by the iTop Data Synchro... so let's do the job of an ETL $this->oModelLookup = new LookupTable('SELECT Model', array('brand_id_friendlyname', 'name')); } protected function ProcessLineBeforeSynchro(&$aLineData, $iLineIndex) { // Process each line of the CSV if (!$this->oOSVersionLookup->Lookup($aLineData, array('osfamily_id', 'osversion_id'), 'osversion_id', $iLineIndex)) { throw New IgnoredRowException('Unknown OS Version'); } if (!$this->oModelLookup->Lookup($aLineData, array('brand_id', 'model_id'), 'model_id', $iLineIndex)) { throw New IgnoredRowException('Unknown Model'); } }
Troubleshooting
When troubleshooting the reconciliation mechanism it is useful
to compare the original (raw) values as reported by the inventory
script with the result of the reconciliation process. Whenever the
method MustProcessBeforeSynchro of a collector returns
true, the framework generates two files inthe
data subdirectory. You can easily compare the values
before/after the lookup by comparing the two CSV files:
-
<collector_name>.raw-<index>.csv: the original data, as produced by the inventory script, -
<collector_name>-<index>.csv: the reprocessed data, to be uploaded to iTop.
Distributing your collector
Default values for the parameters
A collector module can provide default values for its parameters
by providing a file params.distrib.xml in the
collectors folder. If such a file exists, its values
are merged over the equivalent file in the conf
directory.
Adaptation to multiple models
The collector can specify, per class, optional fields which may exist or not in the targeted iTop. For this the collector must implement the method AttributeIsOptional:
- AttributeIsOptional
-
public function AttributeIsOptional($sAttCode): bool { if ($sAttCode == 'services_list') return true; return parent::AttributeIsOptional($sAttCode); }
Data Model Variants
It may happen that the target Data Model has some variants
(depending on the set of modules chosen during the installation).
If a given attribute can be missing in some configurations, you can
tell your collector to accept this variation, by overloading the
method AttributeIsOptional. (This is simpler than
writing a specific collector for each combination).
If an attribute specified in the JSON definition of the Synchro
Data Source is missing, the processing will stop with an error,
unless this attribute is declared as optional. In the later case,
the name of the skipped attribute is recorded in the protected
member variable $this->aSkippedAttributes and the
processing continues. The code of the collector can later check the
content of the array $this->aSkippedAttributes to
determine which fields have to be collected or not.
Example of implementation of AttributeIsOptional as
a method of the VirtualMachineCollector class:
- testcollector.class.inc.php
-
// In your Collector class, overwrite this method to specify iTop fields which can be optional public function AttributeIsOptional($sAttCode) { // If the module Service Management for Service Providers is selected during the setup // there is no "services_list" attribute on VirtualMachines. Let's safely ignore it. if ($sAttCode == 'services_list') return true; return parent::AttributeIsOptional($sAttCode); }
Writing an extensible Collector
Before version 1.3.0 of the collector, activation was controlled
trough the main.php file only.
From version 1.3.0 onwards, the activation can be controlled by the collection plan (see below):
-
You can manually specify which collector to run and their order in XML within
params.local.xml(orparams.distrib.xmlfor a generic collector) -
The collector itself can manage its dependencies and decide upon its activation or not.
Collector base
To benefit from this feature, your collector must be based on collector base 1.3.0 or more.
Collection Plan
A collection plan must be defined for your collector, which goal is to:
-
detect the specificities of the iTop target, like the presence of an optional extension,
-
retrieve from iTop information or objects that your collector depends on,
-
simplify the main.php where the different collector classes were orchestrated.
It implements the CollectionPlan class defined in the collector core, eg. with the LDAP collector:
<?php abstract class LDAPCollectionPlan extends CollectionPlan { public function __construct() { parent::__construct(); } public function Init(): void { parent::Init(); // Add your specificities here } }
The collection plan is instanciated through the
main.php file, eg. for the LDAP collector:
- main.php
-
<?php // Initialize collection plan require_once(APPROOT.'collectors/src/LDAPCollectionPlan.class.inc.php'); require_once(APPROOT.'core/orchestrator.class.inc.php'); Orchestrator::UseCollectionPlan('LDAPCollectionPlan');
Launch sequence
A Launch sequence must be defined in the
params.distrib.xml file. It must list the classes that
you wish to collect and their relative order.
- params.distrib.xml
-
<collectors_launch_sequence type="array"> <collector> <!-- first_Class--> <name>FirstCollector</name> <enable>yes</enable> <rank>10</rank> </collector> <collector> <!-- second_Class--> <name>SecondCollector</name> <enable>yes</enable> <rank>20</rank> </collector> <collector> <!-- third_Class--> <name>ThirdCollector</name> <enable>no</enable> <rank>30</rank> </collector> </collectors_launch_sequence>
Next to the launch sequence, a class can check if all its requirements to run correctly are met or not and potentially decide not to run. This is done through the CheckToLaunch method.
- main.php
-
class MyCollector extends Collector { public function CheckToLaunch($aOrchestratedCollectors): bool { if (conditions_are_met) { return true; } else { return false; } } }
Directory structure
The following structure must be implemented (paths are relative to <my-collector>/collectors/ directory):
-
all json files where the synchro data source are defined reside under /json
-
all PHP files for the different classes to collect are stored under /src
-
the /extensions directory will host add-ons created by customers,
-
all other files like
main.php,params.distrib.xmlormodule.my-collector.phpremain at the root.
Force PHP versions
If your collector needs a specific extension (or a minimum PHP
version), you can specify this dependency by calling the static
method Orchestrator::AddRequirement($sMinRequiredVersion,
$sExtension = 'PHP') in main.php:
For example:
- main.php
-
Orchestrator::AddRequirement('5.4.0'); //This requires at least PHP 5.4 Orchestrator::AddRequirement('1.2.0', 'ldap'); //This requires at least the ldap extension version 1.2.0
Workarounds on limitations
TagSet
Assuming that
-
you want to synchronize the iTop class
MyClass -
this class contain one TagSet field with the code id
tagset_code, -
the primary_key of the Source is stored in an iTop field
primary_key_code
The below code, will store in $aTaxons for each
primary_key, the source value for the TagSet field, then after the
synchronization (so the creation/update of objects in iTop), will
do an API
REST call to update one by one, each object with its TagSet
value.
Just replace MyClass, tagset_code and
primary_key_code with the correct values. Replace also
Collecteur xxx by something meaningful, it will be
stored in iTop history to describe who made that change.
class Mycollector extends XXXCollector { protected $aTaxons; public function Fetch() { $aObject = parent::Fetch(); $this->aTaxons[$aObject['primary_key']] = $aObject['tagset_code']; } public function Synchronize($iMaxChunkSize = 0) { $iErrors = parent::Synchronize($iMaxChunkSize); $oClient = new RestClient(); foreach($this->aTaxons as $primary_key => $sTaxon) { $aResult = $oClient->Update( 'MyClass', array('primary_key_code' => $primary_key), array('tagset_code' => $sTaxon), 'Collecteur xxx' ); if ($aResult['code'] == 0) { utils::Log(LOG_INFO, "TagSet successfully updated."); } else { utils::Log(LOG_ERR, "TagSet update failed. Code: {$aResult['code']}, message: {$aResult['message']}"); } } } }
If the 3rd assumption of the above example is not true, it is still possible to update, by retrieving the iTop object using the reconciliation criteria defined within the DataSynchro, but the code is more complex
class Mycollector extends XXXCollector { protected $aTaxons; protected $aReconciliationKeys; protected function CheckDataSourceDefinition($aSourceDefinition) { $this->aReconciliationKeys = []; if ($aExpectedSourceDefinition['reconciliation_policy'] == 'use_attributes') { foreach($aExpectedSourceDefinition['attribute_list'] as $aAttributeDef) { if ($aAttributeDef['reconcile'] == '1') { $this->aReconciliationKeys[] = $aAttributeDef['attcode']; } } if (count($this->aReconciliationKeys) == 0) { $this->aReconciliationKeys[] = 'id'; // iTop key provided for reconciliation } } return parent::CheckDataSourceDefinition($aSourceDefinition); } public function Fetch() { $aObject = parent::Fetch(); $aTaxon = []; $aTaxon['fields'] = array('tagset_code' => $aObject['tagset_code']); foreach ($this->aReconciliationKeys as $sKeyCode) { if ($sKeyCode == 'id') { $aTaxon['conditions'] = $aObject['primary_key']; } else { $aTaxon['conditions'][] = array( $sKeyCode => $aObject[$sKeyCode] ); } } $this->aTaxons[] = $aTaxon; } public function Synchronize($iMaxChunkSize = 0) { $iErrors = parent::Synchronize($iMaxChunkSize); $oClient = new RestClient(); foreach($this->aTaxons as $aTaxon) { $aResult = $oClient->Update( 'MyClass', $aTaxon['conditions'], $aTaxon['fields'], 'Collecteur xxx' ); if ($aResult['code'] == 0) { utils::Log(LOG_INFO, "TagSet successfully updated."); } else { utils::Log(LOG_ERR, "TagSet update failed. Code: {$aResult['code']}, message: {$aResult['message']}"); } } } }
Files
🚧: Work in progress, code is wrong for now
class Mycollector extends XXXCollector { protected $aUpdatedFiles; // To store the files which must be updated because they have changed public function Fetch() { $aObject = parent::Fetch(); // If the file need to be updated //Then... // Get the file $aFile with name, contents and mimetype // Store the file locally $sFileName = '????'; //TODO provide the path to the file $this->aUpdatedFiles[$aObject['primary_key']] = array( 'data' => base64_encode(file_get_contents($sFileName)), 'filename' => basename($sFileName), 'mimetype' => mime_content_type($sFileName), //Or fixed value e.g. .pdf => 'application/pdf' ); } public function Synchronize($iMaxChunkSize = 0) { $iErrors = parent::Synchronize($iMaxChunkSize); // After objects creation/update in iTop $oClient = new RestClient(); foreach($this->aUpdatedFiles as $primary_key => $aFile) { $aResult = $oClient->Update( 'MyClass', array('primary_key_code' => $primary_key), // Retrieve the iTop object array('file_code' => $aFile), 'Collecteur xxx' ); if ($aResult['code'] == 0) { utils::Log(LOG_INFO, "$aFile['filename'] successfully uploaded."); } else { utils::Log(LOG_ERR, "REST/JSON upload failed for file $aFile['filename']. Code: {$aResult['code']}, message: {$aResult['message']}"); } } } }