Data collector for Ansible
- name:
- Data collector for Ansible
- description:
- Synchronize a set of CIs managed by Ansible into iTop
- version:
- 1.0.0
- release:
- 2023-11-07
- itop-version-min:
- 2.7
- code:
- combodo-ansible-data-collector
- state:
- Pilot
- php-version-max:
- 8.1
This collector enables administrators to automatically feed iTop with relevant and accurate CI information gathered by Ansible controllers, from an inventory of servers, virtual machines… already managed by the Ansible application.
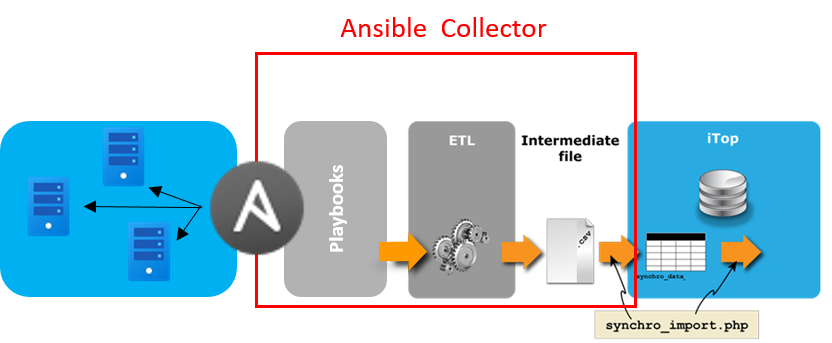
Features
The Data collector for Ansible is a stand-alone PHP software that extracts from Ansible so called “facts”, gathered by the application, informations related to an inventory of CIs and synchronizes them with iTop's CMDB.
-
Collection of facts and extraction of CI informations is done through Ansible playbooks included in the collector,
-
Synchronization follows iTop's built-in Data Synchronization mechanism.
The extension currently focuses on the following classes of objects:
-
Brand
-
Model
-
OS Family
-
OS Version
-
Virtual Machine
-
Logical Interface
-
Server
-
Physical Interface
Data collection can be enhanced by adding further classes to this list. Please, refer to the Q&A chapter below.
Revision History
| Version | Release Date | Comments |
|---|---|---|
| 1.0.0 | 2023-09-24 | First version |
Limitations
The collector is only synchronizing objects managed by Ansible (see above).
Requirements
Usage of the collector requires you to comply with a few points:
-
Ansible application must be in production within the SI.
-
From a system standpoint, you'll need to comply with the requirements expressed in the Data collector Base documentation.
Installation
Installation must be done on an Ansible controller where playbooks can be executed and where iTop application can be reached through https proptocol. Just expand the content of the zip archive in a folder on that machine.
Configuration
The configuration of the application is built by concatenating 4 files:
-
collectors/params.distrib.xml that holds the entries that are specific to the Data collector for Ansible. It should not be modified.
-
collectors/extensions/params.distrib.xml that holds entries that have been created and added by the customer to answer its specific needs. This file is optional.
-
conf/params.distrib.xml that is provided by the collector framework, Data collector Base. It should not be modified.
-
conf/params.local.xml where the collector can be adapted to the specific customer needs.
The collectors/params.distrib.xml configuration file holds parameters that must (for some) or can (for others) be changed when configuring the collector, which is done through the conf/params.local.xml file.
<?xml version="1.0" encoding="UTF-8"?><!-- Default values for parameters. Do NOT alter this file, use params.local.xml instead --> <parameters> <!-- Ansible Parameters --> <gather_facts>no</gather_facts> <raw_directory>data/facts/raw</raw_directory> <csv_directory>data/facts/csv</csv_directory> <!-- Class Parameters --> ... List of Ansible classes to collect with their parameters ... <!-- Class collection sequence --> ... List of classes to collect with the rank in the collection process ... <!-- Synchronization parameters --> <contact_to_notify></contact_to_notify> <synchro_user></synchro_user> <name_prefix>Ansible</name_prefix> <name_postfix>Discovery</name_postfix> <json_placeholders type="hash"> <ansiblebrand_synchro_name>$name_prefix$ Brands $name_postfix$</ansiblebrand_synchro_name> ... Placeholders for other classes ... <synchro_status>production</synchro_status> <full_load_interval>604800</full_load_interval><!-- 7 days (in seconds): 7*24*60*60 --> </json_placeholders> <!-- Mapping tables --> <brand_mapping type="array"> <pattern>/IBM/IBM</pattern> <pattern>/Hewlett Packard/Hewlett-Packard</pattern> <pattern>/Hewlett-Packard/Hewlett-Packard</pattern> <pattern>/Dell/Dell</pattern> <pattern>/.*/%1$s</pattern> </brand_mapping> <model_mapping type="array"> <pattern>/.*/%1$s</pattern> </model_mapping> <os_family_mapping type="array"> <pattern>/Ubuntu/Linux</pattern> <pattern>/RedHat/Linux</pattern> <pattern>/Debian/Linux</pattern> <pattern>/Linux/Linux</pattern> <pattern>/Windows/Windows</pattern> <pattern>/.*/Other</pattern> </os_family_mapping> <os_version_mapping type="array"> <pattern>/.*/%1$s</pattern> </os_version_mapping> <integer_none_mapping type="array"> <pattern>/None/0</pattern> <pattern>/-.*/0</pattern> <pattern>/.*/%1$s</pattern> </integer_none_mapping> <string_none_mapping type="array"> <pattern>/None/</pattern> <pattern>/.*/%1$s</pattern> </string_none_mapping> </parameters>
Ansible parameters
These parameters specify how the collector behaves during the collect.
| Parameter | Meaning | Sample value |
|---|---|---|
| gather_facts | Defines if Ansible facts need to be gathered. Facts may already be collected by other playbooks and reused here if required. |
no / yes |
| raw_directory | Location of the files containing the raw
facts. Raw facts are fact files collected by Ansible. One file per CI is expected here. |
data/facts/raw |
| csv_directory | Location of the csv files created by the
collection process. These CSV file will be used as input file for the CSV collector that is launched during the process. |
data/facts/csv |
Please, refer to the Usage section to clarify the role of these parameters in the collection process.
Class Parameters
Next to the core parameters described here above, the collectors/params.distrib.xml file provides the list of all Ansible classes that need to be discovered together with their subset of parameters that should be synchronized within iTop.
Looking, for instance, at the Server class, we have:
<ansibleservercollector> <csv_file>data/facts/csv/AnsibleServerCollector.csv</csv_file> <has_header>yes</has_header> <collect_condition> <virtualization_role>host</virtualization_role> </collect_condition> <primary_key type="array"> <ansible_attribute>hostname</ansible_attribute> </primary_key> <fields> <brand_id>chassis_vendor</brand_id> <cpu>processor_vcpus</cpu> <description>lsb.description</description> <managementip>default_ipv4.address</managementip> <model_id>product_name</model_id> <name>hostname</name> <osfamily_id>distribution</osfamily_id> <osversion_id>distribution_version</osversion_id> <ram>memtotal_mb</ram> <serialnumber>product_serial</serialnumber> </fields> <defaults> <org_id>Demo</org_id> <status>production</status> </defaults> </ansibleservercollector>
| Parameter | Meaning | Sample value |
|---|---|---|
| csv_file | Name and location of the CSV file containing the
class related data used for the synchronisation The file is created after the collection process |
data/facts/csv/AnsibleServerCollector.csv |
| has_header | Indicates whether there is CSV header that describes your column names or not. | yes |
| collect_condition | List of conditions that must be met to consider a given fact as part of the class to process | <virtualization_role>host</virtualization_role> |
| primary_key | Parameter to be used for the primary_key | <ansible_attribute>hostname</ansible_attribute> |
| fields | List of object's fields to be considered by the synchro engine with their iTop equivalent | <brand_id>chassis_vendor</brand_id> |
| defaults | List of default values to be used, if required | <org_id>Demo</org_id> |
Class collection sequence
This section defines the list of classes that will be collected and in which order. It enables as well the possibility to deactivate the collection of a class.
<collectors_launch_sequence type="array"> <!-- Brand --> <collector> <name>AnsibleBrandCollector</name> <enable>yes</enable> <rank>1</rank> </collector> <!-- Model --> <collector> <name>AnsibleModelCollector</name> <enable>yes</enable> <rank>2</rank> </collector> <!-- OS Family --> <collector> <name>AnsibleOSFamilyCollector</name> <enable>yes</enable> <rank>3</rank> </collector> <!-- OS Version --> <collector> <name>AnsibleOSVersionCollector</name> <enable>yes</enable> <rank>4</rank> </collector> <!-- Server --> <collector> <name>AnsibleServerCollector</name> <enable>yes</enable> <rank>5</rank> </collector> <!-- VirtualMachine --> <collector> <name>AnsiblePhysicalInterfaceCollector</name> <enable>yes</enable> <rank>6</rank> </collector> <collector> <name>AnsibleVirtualMachineCollector</name> <enable>yes</enable> <rank>7</rank> </collector> <!-- LogicalInterface --> <collector> <name>AnsibleLogicalInterfaceCollector</name> <enable>yes</enable> <rank>8</rank> </collector> </collectors_launch_sequence>
| Parameter | Meaning | Sample value |
|---|---|---|
| name | Name of the Ansible class collector | AnsibleBrandCollector |
| enable | Enable or disable its collect | yes / no |
| rank | Relative rank in the collection | 5 |
Synchro data source parameters
These parameters are dedicated to the synchronization data sources that the collector creates. Some of them must or may be adjusted to meet customers' own environment.
| Parameter | Meaning | Sample value |
|---|---|---|
| contact_to_notify | The email address of an existing contact in iTop to be notified of the results of the synchronization. | john.doe@demo.com |
| synchro_user | If the user account used for running this synchronization is not an Administrator, then its login must be specified here, since iTop allows only the administrators and the specified user to run the synchronization. | |
| name_prefix | String used to prefix the name of all Ansible synchro data sources | Azure |
| name_postfix | String used postfix the name of all Ansible synchro data sources | Discovery |
| $name_prefix$ <Ansible_Class> $name_postfix$ | Name of the synchro data source for the given Azure Class | Ansible Server Discovery |
| full_load_interval | The delay (expressed in seconds) between two complete imports of the data. The objects which have not been detected by the collector during a timespan longer than this interval will be considered as obsolete and marked as such in iTop. Adjust this value depending on the scheduling recurrence. | 604800 |
Mapping tables
This section groups the mapping tables used by the collector.
| Parameter | Meaning |
|---|---|
| brand_mapping | Mapping table for brands |
| model_mapping | Mapping table for models |
| os_family_mapping | Mapping table for OS families |
| os_version_mapping | Mapping table for OS versions |
| integer_none_mapping | Mapping table for “empty” integer values |
| string_none_mapping | Mapping table for “empty” string values |
The collectors/extensions/params.distrib.xml configuration file holds parameters to collect additional classes required by a customer.
<?xml version="1.0" encoding="UTF-8"?><!-- Default values for parameters. Do NOT alter this file, use params.local.xml instead --> <parameters> <!-- Class Parameters --> ... List of additional classes with their parameters ... <!-- Class collection sequence --> ... List of additional classes to collect with the rank in the collection process ... </parameters>
iTop Connection parameters
Finally, the conf/params.local.xml file hosts all the parameters that are specific to the customer, like the connection parameters that are required to connect to iTop application.
| Parameter | Meaning | Sample value |
|---|---|---|
| itop_url | URL to the iTop Application | https://localhost/myitop |
| itop_login | Login (user account) for connecting to iTop. Must have admin rights with rest profile for executing the data synchro | admin |
| itop_password | Password for the iTop account | admin_pwd |
Usage
Initialization
Launch of the Ansible collector will be driven by the command and parameters defined in the usage section of iTop Data collector base. Once launched, first action of the collector will be to define its collection plan, based on the list of classes that have been enabled in the configuration file. Configuration is, then, built and synchro data sources are updated in iTop.
Collection - Step #1
The collection process itself will start just aferwards. It will get or gather information on all the CIs that Ansible manages. This list of CIs is defined in the default inventory used by Ansible. The gathering task is done through a playbook embedded in the collector that ultimately saves the information under the raw_directory, in one dedicated file per CI. It may be possible that this information is already available on the Ansible controller and that, as a consequence, there is no need to collect it again. Should that be the case, just set the gather_facts parameter to no and make the raw_directory point to the location where these files reside.
Then, for each of the classes that need to be synchronized, the collection process will extract the valuable informations from the facts files and store them in a csv file. Here again, this action is done through playbooks embedded in the collector. Here is the detail of what happens for the collection of a given class:
-
A csv file with just a header is created under the csv_directory,
-
The collect_condition parameter of the class defines the criteria that must be met in order to consider the fact for the class collection,
-
If the condition is met, then the fact file is analysed by the collector,
-
Valuable information defined under the fields section is extracted and added to the csv file.
If we consider the collection of the class Server as an exemple.
-
csv file data/facts/csv/AnsibleServerCollector.csv is created,
-
The collect_condition is: <virtualization_role>host</virtualization_role>.
-
Parameter virtualization_role must be present in the file fact and must be set to host to consider the fact as a Server
-
-
Fields chassis_vendor, processor_vcpus, lsb.description, default_ipv4.address, product_name, hostname, distribution, distribution_version, memtotal_mb and product_serial are read from the fact and stored in the csv file
Collection - Step #2
From there, the Data Collector for Ansible will behave as a standard CSV collector. It will use the csv file previously built as an entry file to build the standard class-n.csv files (AnsibleServerCollector-1.csv in the above exemple).
Synchronization
This final step runs according to the Data collector Base standard.
Questions & Answers
Question: how can I add Ansible classes to the
collection plan
Answer: Other classes than the ones listed by default in the
collector can be added to it. For that purpose, we highly recommend
to use the extensibility mechanism.
-
Within the <your_collector>/collectors/extensions/ directory:
-
Create a params.distrib.xml file
-
Add a class entry in it, like what is done in the default Class Parameter section,
-
Add an extensions_collectors_launch_sequence similarly to what is done in the Class Collection Sequence section,
-
-
Create the json/MyNewClassCollector.json file that describes the synchro data source of the new class,
-
Create the src/MyNewClassCollector.class.inc.php file that contains the collector specificities for the class (REST API URL, dependency parameters…),
-
-
And that's it

You may refer to what already exists for other classes as examples.