Data collector for Azure
- name:
- Data collector for Azure
- description:
- Synchronize a set of Microsoft Azure CIs into iTop
- version:
- 2.0.1
- release:
- 2024-09-10
- itop-version-min:
- 2.7
- code:
- combodo-azure-data-collector
- state:
- stable
- php-version-max:
- 8.3
This collector enables administrators to automatically feed iTop with relevant and accurate Azure cloud computing information. It relies on the Azure modelization that the Data model for Microsoft Azure extension is bringing to iTop CMDB.
Features
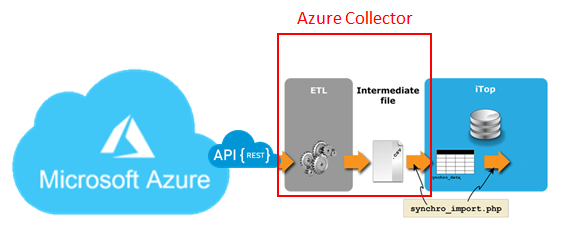
The Data collector for Azure is a stand-alone PHP software that connects to Azure, retrieves objects from a set of subscriptions, all belonging to a given Tenant, and synchronize them with iTop's CMDB.
-
Connection to Azure is made through Azure OAUTH2 authentication,
-
Retrieval of objects relies on Azure REST API that extracts data in JSON format,
-
Selection of Subscriptions to consider is made in iTop,
-
Synchronization follows iTop's built-in Data Synchronization mechanism.
The Data collector for Azure relies on the Data model for Microsoft Azure extension where Azure objects are modelized for iTop. The number of object types being significant within Azure cloud computing, the extension only focuses on a subset of these objects:
-
General
-
Location
-
Resource Group
-
SKU
-
Subscription
-
Collection of resources that belong to a given subscription can be enabled or disabled on a per subscription basis
-
-
-
Compute
-
VM
-
-
Storage
-
Disk
-
Storage Account
-
-
Database
-
DB Server
-
MariaDB Database
-
MySQL Database
-
MS SQL Database
-
PostgreSQL Database
-
-
Container
-
App Service
-
Kubernetes Service
-
-
Networking
-
IPv4 / IPv6 addresses (if “IPAM for iTop” is installed)
-
IPv4 / IPv6 subnets (if “IPAM for iTop” is installed)
-
Load Balancer
-
Load Balancer Frontend IP Config
-
Network Interface
-
Network Interface Card IP Config
-
Private Endpoint
-
Public IP Address
-
Subnet
-
VNet
-
VNet Gateway
-
Data collection can be enhanced by adding further Azure classes to this list. Please, refer to the Q&A chapter below.
Revision History
| Version | Release Date | Comments |
|---|---|---|
| 2.0.1 | 2024-09-03 | N°6368 - Attribute azuretags is missing in the
list of optional attributes for Location and Azure Resource
Group N°7706 - Wrong PHP constants used in some collector classes |
| 2.0.0 | 2023-05-16 | * Add Azure IP related classes to the
collection * Increase the number of collected attributes per class * Collect TAGs * Handle the optional presence of TeemIp extensions and adapt synchronisation accordingly |
| 1.0.4 | 2022-11-18 | First version |
Limitations
The collector is only synchronizing a limited subset of Azure objects (see above).
Collection of IPv6 resources (IPv6 addresses, IPv6 subnets…) is restricted to the iTop version used.
Requirements
Usage of the collector requires you to comply with a few points:
-
The Azure objects synchronized by the collector must exist in iTop as CMDB CIs. This can be done with the Data model for Microsoft Azure extension that precisely enhanced iTop CMDB with Azure objects.
-
In order to browse Azure computing environment, you'll need an Azure account (see service principal) that allows you to read Azure resources.
-
From a system standpoint, you'll need to comply with the requirements expressed in the Data collector Base documentation.
Installation
Simply expand the content of the zip archive into a folder on the machine where the collector will be run.
Configuration
The configuration of the application is built by concatenating 4 files:
-
collectors/params.distrib.xml that holds the entries that are specific to the Data collector for Azure. It should not be modified.
-
collectors/extensions/params.distrib.xml that holds entries that have been created and added by the customer to answer its specific needs. This file is optional.
-
conf/params.distrib.xml that is provided by the collector framework, Data collector Base. It should not be modified.
-
conf/params.local.xml where the collector can be adapted to the specific customer needs.
The collectors/params.distrib.xml configuration file holds parameters that must (for some) or can (for others) be changed when configuring the collector, which is done through the conf/params.local.xml file.
<?xml version="1.0" encoding="UTF-8"?><!-- Default values for parameters. Do NOT alter this file, use params.local.xml instead --> <parameters> <!-- Connection parameters--> <!-- iTop Parameters --> <itop_url>http://myitop.com</itop_url> <itop_login>admin</itop_login> <itop_password>admin</itop_password> <!-- Microsoft links --> <microsoft_login_url>https://login.microsoftonline.com/</microsoft_login_url> <microsoft_auth_mode>/oauth2/token</microsoft_auth_mode> <microsoft_resource>https://management.azure.com/</microsoft_resource> <!-- Client's credentials --> <ms_clientid></ms_clientid> <ms_clientsecret></ms_clientsecret> <ms_tenantid></ms_tenantid> <!-- *** Azure Class Parameters *** --> ... List of Azure classes with their parameters ... <!-- Class collection sequence --> ... List of classes to collect with the rank in the collection process ... <!-- Synchro data source parameters --> <contact_to_notify></contact_to_notify> <synchro_user>admin</synchro_user> <name_prefix>Azure</name_prefix> <name_postfix>Discovery</name_postfix> <json_placeholders> <ms_tenantid_short></ms_tenantid_short> <azureappservice_synchro_name>$name_prefix$ App Services $name_postfix$</azureappservice_synchro_name> ... Placeholders for other classes ... <synchro_status>production</synchro_status> <full_load_interval>604800</full_load_interval><!-- 7 days (in seconds): 7*24*60*60 --> </json_placeholders> <!-- Mapping tables --> <subscription_status_mapping type="array"> <pattern>/Deleted/obsolete</pattern> <pattern>/Disabled/implementation</pattern> <pattern>/Enabled/production</pattern> <pattern>/PastDue/obsolete</pattern> <pattern>/Warned/implementation</pattern> </subscription_status_mapping> <disk_encryption_mapping type="array"> <pattern>/true/enabled</pattern> <pattern>/false/disabled</pattern> <pattern>/.*/disabled</pattern> </disk_encryption_mapping> </parameters>
The collectors/extensions/params.distrib.xml configuration file holds parameters to collect additional classes required by a customer.
<?xml version="1.0" encoding="UTF-8"?><!-- Default values for parameters. Do NOT alter this file, use params.local.xml instead --> <parameters> <!-- Azure Class Parameters --> ... List of additional Azure classes with their parameters ... <!-- Class collection sequence --> ... List of additional classes to collect with the rank in the collection process ... <!-- Synchronization parameters --> <json_placeholders> <azuremyclass_synchro_name>$name_prefix$ My Class $name_postfix$</azuremyclass_synchro_name> ... Placeholders for other additional classes ... </json_placeholders> </parameters>
Connection parameters
This set of parameters is required to connect to iTop application or to Microsoft Azure environment. Some of them must or may be adjusted to meet customers' own environment.
| Parameter | Meaning | Sample value |
|---|---|---|
| itop_url | URL to the iTop Application | https://localhost/myitop |
| itop_login | Login (user account) for connecting to iTop. Must have admin rights with rest profile for executing the data synchro | admin |
| itop_password | Password for the iTop account | admin_pwd |
| microsoft_login_url | URL to be used by the collector to log into Azure and start the authentication process | https://login.microsoftonline.com/ |
| microsoft_auth_mode | Specifies the authentication process - OAUTH2 for the Azure collector | /oauth2/token |
| microsoft_resource | URL to the Azure REST API | https://management.azure.com/ |
| ms_tenantid | Tenant ID is the unique identifier of your Azure Active Directory instance. A Tenant ID allows you to register and manage your apps. | 2d74zb091-b7fe-4e14-868b-4e9a3f887a60 |
| ms_clientid | Client ID is the unique identifier of your application created in Azure Active Directory. | 7ed0fdef-abcd-4fd0-8364-da5fde498765 |
| ms_clientsecret | Secret key associated to the Client ID | fJ4eQ~rG75DPd4aadrBodZvKxFtxOhnX2XrO |
Synchro data source parameters
These are dedicated to the synchronization data sources that the collector creates. Some of them must or may be adjusted to meet customers' own environment.
| Parameter | Meaning | Sample value |
|---|---|---|
| contact_to_notify | The email address of an existing contact in iTop to be notified of the results of the synchronization. | john.doe@demo.com |
| synchro_user | If the user account used for running this synchronization is not an Administrator, then its login must be specified here, since iTop allows only the administrators and the specified user to run the synchronization. | |
| name_prefix | String used to prefix the name of all Azure synchro data sources | Azure |
| name_postfix | String used postfix the name of all Azure synchro data sources | Discovery |
| $name_prefix$ <Azure_Class> $name_postfix$ | Name of the synchro data source for the given Azure Class | Azure App Services Discovery |
| ms_tenantid_short | Sub string of the Tenant ID that allows you to
differentiate different synchro data sources working on different
Tenants (1 collector should be used per Tenant - see above). That string is appended to the name of the synchro data source, in iTop. |
4e9a3f887a60 |
| full_load_interval | The delay (expressed in seconds) between two complete imports of the data. The objects which have not been detected by the collector during a timespan longer than this interval will be considered as obsolete and marked as such in iTop. Adjust this value depending on the scheduling recurrence. | 604800 |
Mapping tables
This section groups the mapping tables used by the collector.
| Parameter | Meaning |
|---|---|
| subscription_status_mapping | Mapping table for subscription status |
| disk_encryption_mapping | Mapping table for disc encryption status |
| ipv4_subnet_mask_mapping | Mapping between CIDR and FQDN mask sizes |
Azure Class Parameters
Next to the core parameters described here above, the collectors/params.distrib.xml file provides the list of all Azure classes that need to be discovered together with their subset of parameters that should be synchronized within iTop. Since the retrieval of Azure data is made in JSON format, this list must be aligned with the requirements expected by the standard JSON collector defined in the data collector base.
Looking, for instance, at the App Service class, we have:
<azureappserviceazurecollector> <ms_class>sites</ms_class> <api_version>2021-02-01</api_version> <jsonfile>data/AzureAppServices.json</jsonfile> <path>value</path> <fields> <primary_key>id</primary_key> <app_service_plan>properties/serverFarmId</app_service_plan> <azureid>id</azureid> <azureresourcegroup_id>azureresourcegroup_id</azureresourcegroup_id> <azuresubscription_id>azuresubscription_id</azuresubscription_id> <azuretags>azuretags</azuretags> <business_criticity>business_criticity</business_criticity> <ftps_hostname>properties/ftpsHostName</ftps_hostname> <location_id>location</location_id> <name>name</name> <org_id>org_id</org_id> <provisioning_status>properties/state</provisioning_status> <status>state</status> <url>url</url> </fields> <defaults> <app_service_plan></app_service_plan> <azureresourcegroup_id></azureresourcegroup_id> <azuresubscription_id></azuresubscription_id> <azuretags></azuretags> <business_criticity>medium</business_criticity> <ftps_hostname></ftps_hostname> <org_id>Demo</org_id> <provisioning_status></provisioning_status> <status>implementation</status> <url></url> </defaults> </azureappserviceazurecollector>
| Parameter | Meaning | Sample value |
|---|---|---|
| ms_class | Name of the Azure class | AppService |
| api_version | Version of the Microsoft REST API used to retrieve class data | 2021-02-01 |
| jsonfile | Define the relative path to the JSON file where Azure data have been extracted | data/AzureAppServices.json |
| path | Path to find the data to synchronize in JSON file | value |
| fields | List of objects' fields to be considered by the synchro engine | See above |
| defaults | List of default values to be used, if required | See above |
Class collection sequence
This section defines the list of classes that will be collected and in which order. It enables as well the possibility to deactivate the collection of a class.
<collectors_launch_sequence type="array"> <!-- Warning: order is important for some classes: 1 to 3 and , the ones listed with numbers or letters; alphabetical order is ok for others --> <!-- Subscriptions --> <collector> <name>AzureSubscriptionAzureCollector</name> <enable>no</enable> <rank>1</rank> </collector> <!-- Locations --> <collector> <name>AzureLocationAzureCollector</name> <enable>no</enable> <rank>2</rank> </collector> <!-- Resources group --> <collector> <name>AzureResourceGroupAzureCollector</name> <enable>no</enable> <rank>3</rank> </collector> <!-- SKUs --> <collector> <name>AzureSKUAzureCollector</name> <enable>no</enable> <rank>4</rank> </collector> ... </collectors_launch_sequence>
| Parameter | Meaning | Sample value |
|---|---|---|
| name | Name of the Azure class collector | AzureAppServiceAzureCollector |
| enable | Enable or disable its collect | yes / no |
| rank | Relative rank in the collection | 30 |
On iTop side
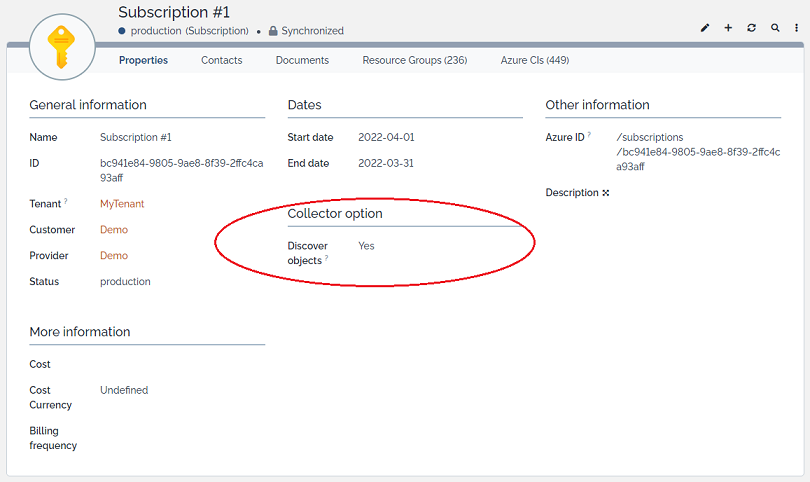
Next to the configuration of the collector itself, actions are required on iTop, at the subscription's level, to fully enable the discovery of Azure objects:
-
Once subscriptions are discovered and documented in iTop, their “Discover objects” attributes is set to 'no' by default,
-
In order to enable their discovery by the collector, this parameter needs to be switched to 'yes'.
Usage
Launch of the Azure collector will be driven by the command and parameters defined in the usage section of iTop Data collector base. Once launched, first action of the collector will be to define its collection plan, based on the list of classes that have been enabled in the configuration file.
The very first time that the collector is running, it will focus on the Subscriptions, if these have been enabled (if not, no collection will be made). Only the subscriptions that belong to the Tenant defined in the configuration file will be discovered. Should you need to collect subscriptions belonging to different Tenants, then dedicated collectors will need to be deployed for each of these Tenants.
Once subscriptions have been discovered and synchronized in iTop, CMDB manager will need to decide whether these subscriptions will have to be further discovered or not. Refer to the previous chapter for details on that step.
At this stage, Azure data collector can be launched again in order to collect all classes that the configuration has enabled. Once again, collector will start by building its collection plan and once done:
-
Configuration files will be consolidated,
-
Synchronisation data sources will be created or updated if required,
-
Authentication to Azure environment will be made (see below),
-
Collection of Azure classes will be made by invoking Azure REST API and extracted data will be stored under the local “data” directory, in JSON format,
-
Synchronisation will run and Azure objects will be pushed to iTop.
As a summary:
-
Discover and collect Azure subscriptions on the first collector run,
-
Connect to iTop and check the subscriptions that need to be scanned,
-
Launch the collector a second time to collect the Resource Groups contained in the subscriptions to be discovered,
-
Run the collector subsequently to collect and synchronize the objects that belong to the different Resource Groups.
-
Azure SKUs and Locations being static objects, these may be collected from time to time only.
Questions & Answers
Question: how does the authentication mechanism work
?
Answer: Azure requests OAUTH2 authentication to retrieve data
through its REST API. This grants to
users limited access to its protected resources:
-
OAuth separates the role of the client from the resource owner.
-
The client requests access to the resources controlled by the resource owner and hosted by the resource server. The resource server issues access tokens with the approval of the resource owner. The client uses the access tokens to access the protected resources hosted by the resource server.
Within the Azure collector, the authentication status is checked before starting the collection of every Azure class of object. This is done by reading some parameters contained in the data/BearerToken.csv file. If the file does not exist or if it doesn't contain any Bearer Token or if the token has expired, the collector is considered as disconnected from Azure and a new authentication process needs to start. Otherwise, if parameters are fine, collection may proceed with the Bearer Token used as a parameter.
If a new authentication needs to be initiated:
-
Collector posts an authentication request toward Azure, providing the 3 configuration parameters ms_tenantid, ms_clientid and ms_clientsecret that have been defined for that purpose,
-
If authentication fails, error messages is logged and collection stops.
-
If authentication succeeds:
-
A Bearer Token associated to an expiration delay is provided by Azure,
-
These parameters are stored in the file data/BearerToken.csv.
-
Data collection for the given class proceeds.
-
As a summary, for each class of object: 
Question: how can I add Azure classes to the collection
plan
Answer: Other classes than the ones listed by default in the
collector can be added to it. For that purpose, we highly recommend
to use the extensibility mechanism that is available since version
2 of the collector (version 1.3.0 of iTop Data Collector Base).
-
Make sure the class (MyNewClass) has been modelized in iTop (Through the Data model for Microsoft Azure extension for instance).
-
Within the <your_collector>/collectors/extensions/ directory:
-
Create a params.distrib.xml file
-
Add a class entry in it, like what is done in the default Azure Class Parameter section,
-
Add a extensions_collectors_launch_sequence similarly to what is done in the Class Collection Sequence section,
-
-
Create the json/MyNewClassAzureCollector.json file that describes the synchro data source of the new class,
-
Create the src/MyNewClassAzureCollector.class.inc.php file that contains the collector specificities for the class (REST API URL, dependency parameters…),
-
-
And that's it 🙂
You may refer to what already exists for other classes as examples.
Question: how can I take advantage of Azure tags within
the collector
Answer: Tags, in Azure, are name/value pairs that enable you to
categorize resources and view consolidated billing by applying the
same tag to multiple resources and resource groups. They can be
exported as raw values, without being altered by Azure API. When modelized as
new attributes in iTop, they can be used to reconcile objects, link
objects together or just add information to an object.
You may create tags in Azure as follows:

then,

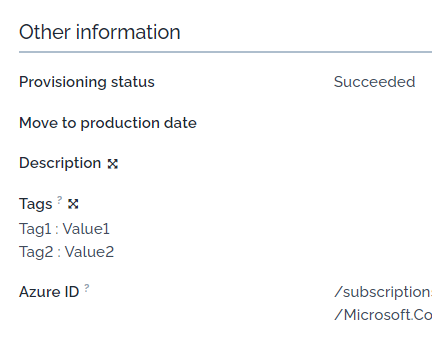
and finally:
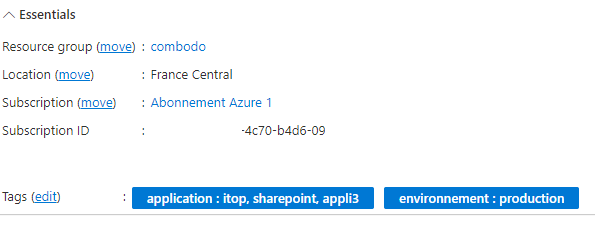
Starting with version 2.0.0 of the collector, tags will be imported as is, in a raw text attribute of Azure objects and will be displayed in the “Other information” section.